Fundamental Concepts in the Design of Experiments 5th Edition
Design of tasks set to uncover from

The design of experiments (DOE, DOX, or experimental design) is the design of any task that aims to describe and explain the variation of information under conditions that are hypothesized to reflect the variation. The term is generally associated with experiments in which the design introduces conditions that directly affect the variation, but may also refer to the design of quasi-experiments, in which natural conditions that influence the variation are selected for observation.
In its simplest form, an experiment aims at predicting the outcome by introducing a change of the preconditions, which is represented by one or more independent variables, also referred to as "input variables" or "predictor variables." The change in one or more independent variables is generally hypothesized to result in a change in one or more dependent variables, also referred to as "output variables" or "response variables." The experimental design may also identify control variables that must be held constant to prevent external factors from affecting the results. Experimental design involves not only the selection of suitable independent, dependent, and control variables, but planning the delivery of the experiment under statistically optimal conditions given the constraints of available resources. There are multiple approaches for determining the set of design points (unique combinations of the settings of the independent variables) to be used in the experiment.
Main concerns in experimental design include the establishment of validity, reliability, and replicability. For example, these concerns can be partially addressed by carefully choosing the independent variable, reducing the risk of measurement error, and ensuring that the documentation of the method is sufficiently detailed. Related concerns include achieving appropriate levels of statistical power and sensitivity.
Correctly designed experiments advance knowledge in the natural and social sciences and engineering. Other applications include marketing and policy making. The study of the design of experiments is an important topic in metascience.
History [edit]
Statistical experiments, following Charles S. Peirce [edit]
A theory of statistical inference was developed by Charles S. Peirce in "Illustrations of the Logic of Science" (1877–1878)[1] and "A Theory of Probable Inference" (1883),[2] two publications that emphasized the importance of randomization-based inference in statistics.[3]
Randomized experiments [edit]
Charles S. Peirce randomly assigned volunteers to a blinded, repeated-measures design to evaluate their ability to discriminate weights.[4] [5] [6] [7] Peirce's experiment inspired other researchers in psychology and education, which developed a research tradition of randomized experiments in laboratories and specialized textbooks in the 1800s.[4] [5] [6] [7]
Optimal designs for regression models [edit]
Charles S. Peirce also contributed the first English-language publication on an optimal design for regression models in 1876.[8] A pioneering optimal design for polynomial regression was suggested by Gergonne in 1815. In 1918, Kirstine Smith published optimal designs for polynomials of degree six (and less).[9] [10]
Sequences of experiments [edit]
The use of a sequence of experiments, where the design of each may depend on the results of previous experiments, including the possible decision to stop experimenting, is within the scope of sequential analysis, a field that was pioneered[11] by Abraham Wald in the context of sequential tests of statistical hypotheses.[12] Herman Chernoff wrote an overview of optimal sequential designs,[13] while adaptive designs have been surveyed by S. Zacks.[14] One specific type of sequential design is the "two-armed bandit", generalized to the multi-armed bandit, on which early work was done by Herbert Robbins in 1952.[15]
Fisher's principles [edit]
A methodology for designing experiments was proposed by Ronald Fisher, in his innovative books: The Arrangement of Field Experiments (1926) and The Design of Experiments (1935). Much of his pioneering work dealt with agricultural applications of statistical methods. As a mundane example, he described how to test the lady tasting tea hypothesis, that a certain lady could distinguish by flavour alone whether the milk or the tea was first placed in the cup. These methods have been broadly adapted in biological, psychological, and agricultural research.[16]
- Comparison
- In some fields of study it is not possible to have independent measurements to a traceable metrology standard. Comparisons between treatments are much more valuable and are usually preferable, and often compared against a scientific control or traditional treatment that acts as baseline.
- Randomization
- Random assignment is the process of assigning individuals at random to groups or to different groups in an experiment, so that each individual of the population has the same chance of becoming a participant in the study. The random assignment of individuals to groups (or conditions within a group) distinguishes a rigorous, "true" experiment from an observational study or "quasi-experiment".[17] There is an extensive body of mathematical theory that explores the consequences of making the allocation of units to treatments by means of some random mechanism (such as tables of random numbers, or the use of randomization devices such as playing cards or dice). Assigning units to treatments at random tends to mitigate confounding, which makes effects due to factors other than the treatment to appear to result from the treatment.
- The risks associated with random allocation (such as having a serious imbalance in a key characteristic between a treatment group and a control group) are calculable and hence can be managed down to an acceptable level by using enough experimental units. However, if the population is divided into several subpopulations that somehow differ, and the research requires each subpopulation to be equal in size, stratified sampling can be used. In that way, the units in each subpopulation are randomized, but not the whole sample. The results of an experiment can be generalized reliably from the experimental units to a larger statistical population of units only if the experimental units are a random sample from the larger population; the probable error of such an extrapolation depends on the sample size, among other things.
- Statistical replication
- Measurements are usually subject to variation and measurement uncertainty; thus they are repeated and full experiments are replicated to help identify the sources of variation, to better estimate the true effects of treatments, to further strengthen the experiment's reliability and validity, and to add to the existing knowledge of the topic.[18] However, certain conditions must be met before the replication of the experiment is commenced: the original research question has been published in a peer-reviewed journal or widely cited, the researcher is independent of the original experiment, the researcher must first try to replicate the original findings using the original data, and the write-up should state that the study conducted is a replication study that tried to follow the original study as strictly as possible.[19]
- Blocking
- Blocking is the non-random arrangement of experimental units into groups (blocks) consisting of units that are similar to one another. Blocking reduces known but irrelevant sources of variation between units and thus allows greater precision in the estimation of the source of variation under study.
- Orthogonality
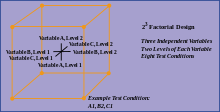
Example of orthogonal factorial design
- Orthogonality concerns the forms of comparison (contrasts) that can be legitimately and efficiently carried out. Contrasts can be represented by vectors and sets of orthogonal contrasts are uncorrelated and independently distributed if the data are normal. Because of this independence, each orthogonal treatment provides different information to the others. If there are T treatments and T – 1 orthogonal contrasts, all the information that can be captured from the experiment is obtainable from the set of contrasts.
- Factorial experiments
- Use of factorial experiments instead of the one-factor-at-a-time method. These are efficient at evaluating the effects and possible interactions of several factors (independent variables). Analysis of experiment design is built on the foundation of the analysis of variance, a collection of models that partition the observed variance into components, according to what factors the experiment must estimate or test.
Example [edit]

This example of design experiments is attributed to Harold Hotelling, building on examples from Frank Yates.[20] [21] [13] The experiments designed in this example involve combinatorial designs.[22]
Weights of eight objects are measured using a pan balance and set of standard weights. Each weighing measures the weight difference between objects in the left pan and any objects in the right pan by adding calibrated weights to the lighter pan until the balance is in equilibrium. Each measurement has a random error. The average error is zero; the standard deviations of the probability distribution of the errors is the same number σ on different weighings; errors on different weighings are independent. Denote the true weights by

We consider two different experiments:
- Weigh each object in one pan, with the other pan empty. Let X i be the measured weight of the object, for i = 1, ..., 8.
- Do the eight weighings according to the following schedule and let Y i be the measured difference for i = 1, ..., 8:

- Then the estimated value of the weight θ 1 is

- Similar estimates can be found for the weights of the other items. For example
![{\displaystyle {\begin{aligned}{\widehat {\theta }}_{2}&={\frac {Y_{1}+Y_{2}-Y_{3}-Y_{4}+Y_{5}+Y_{6}-Y_{7}-Y_{8}}{8}}.\\[5pt]{\widehat {\theta }}_{3}&={\frac {Y_{1}+Y_{2}-Y_{3}-Y_{4}-Y_{5}-Y_{6}+Y_{7}+Y_{8}}{8}}.\\[5pt]{\widehat {\theta }}_{4}&={\frac {Y_{1}-Y_{2}+Y_{3}-Y_{4}+Y_{5}-Y_{6}+Y_{7}-Y_{8}}{8}}.\\[5pt]{\widehat {\theta }}_{5}&={\frac {Y_{1}-Y_{2}+Y_{3}-Y_{4}-Y_{5}+Y_{6}-Y_{7}+Y_{8}}{8}}.\\[5pt]{\widehat {\theta }}_{6}&={\frac {Y_{1}-Y_{2}-Y_{3}+Y_{4}+Y_{5}-Y_{6}-Y_{7}+Y_{8}}{8}}.\\[5pt]{\widehat {\theta }}_{7}&={\frac {Y_{1}-Y_{2}-Y_{3}+Y_{4}-Y_{5}+Y_{6}+Y_{7}-Y_{8}}{8}}.\\[5pt]{\widehat {\theta }}_{8}&={\frac {Y_{1}+Y_{2}+Y_{3}+Y_{4}+Y_{5}+Y_{6}+Y_{7}+Y_{8}}{8}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8b6970abd1a6e69f062cddd667a1ea60088e94c8)
The question of design of experiments is: which experiment is better?
The variance of the estimate X 1 of θ 1 is σ 2 if we use the first experiment. But if we use the second experiment, the variance of the estimate given above is σ 2/8. Thus the second experiment gives us 8 times as much precision for the estimate of a single item, and estimates all items simultaneously, with the same precision. What the second experiment achieves with eight would require 64 weighings if the items are weighed separately. However, note that the estimates for the items obtained in the second experiment have errors that correlate with each other.
Many problems of the design of experiments involve combinatorial designs, as in this example and others.[22]
Avoiding false positives [edit]
False positive conclusions, often resulting from the pressure to publish or the author's own confirmation bias, are an inherent hazard in many fields. A good way to prevent biases potentially leading to false positives in the data collection phase is to use a double-blind design. When a double-blind design is used, participants are randomly assigned to experimental groups but the researcher is unaware of what participants belong to which group. Therefore, the researcher can not affect the participants' response to the intervention. Experimental designs with undisclosed degrees of freedom are a problem.[23] This can lead to conscious or unconscious "p-hacking": trying multiple things until you get the desired result. It typically involves the manipulation – perhaps unconsciously – of the process of statistical analysis and the degrees of freedom until they return a figure below the p<.05 level of statistical significance.[24] [25] So the design of the experiment should include a clear statement proposing the analyses to be undertaken. P-hacking can be prevented by preregistering researches, in which researchers have to send their data analysis plan to the journal they wish to publish their paper in before they even start their data collection, so no data manipulation is possible (https://osf.io). Another way to prevent this is taking the double-blind design to the data-analysis phase, where the data are sent to a data-analyst unrelated to the research who scrambles up the data so there is no way to know which participants belong to before they are potentially taken away as outliers.
Clear and complete documentation of the experimental methodology is also important in order to support replication of results.[26]
Discussion topics when setting up an experimental design [edit]
An experimental design or randomized clinical trial requires careful consideration of several factors before actually doing the experiment.[27] An experimental design is the laying out of a detailed experimental plan in advance of doing the experiment. Some of the following topics have already been discussed in the principles of experimental design section:
- How many factors does the design have, and are the levels of these factors fixed or random?
- Are control conditions needed, and what should they be?
- Manipulation checks; did the manipulation really work?
- What are the background variables?
- What is the sample size. How many units must be collected for the experiment to be generalisable and have enough power?
- What is the relevance of interactions between factors?
- What is the influence of delayed effects of substantive factors on outcomes?
- How do response shifts affect self-report measures?
- How feasible is repeated administration of the same measurement instruments to the same units at different occasions, with a post-test and follow-up tests?
- What about using a proxy pretest?
- Are there lurking variables?
- Should the client/patient, researcher or even the analyst of the data be blind to conditions?
- What is the feasibility of subsequent application of different conditions to the same units?
- How many of each control and noise factors should be taken into account?
The independent variable of a study often has many levels or different groups. In a true experiment, researchers can have an experimental group, which is where their intervention testing the hypothesis is implemented, and a control group, which has all the same element as the experimental group, without the interventional element. Thus, when everything else except for one intervention is held constant, researchers can certify with some certainty that this one element is what caused the observed change. In some instances, having a control group is not ethical. This is sometimes solved using two different experimental groups. In some cases, independent variables cannot be manipulated, for example when testing the difference between two groups who have a different disease, or testing the difference between genders (obviously variables that would be hard or unethical to assign participants to). In these cases, a quasi-experimental design may be used.
Causal attributions [edit]
In the pure experimental design, the independent (predictor) variable is manipulated by the researcher – that is – every participant of the research is chosen randomly from the population, and each participant chosen is assigned randomly to conditions of the independent variable. Only when this is done is it possible to certify with high probability that the reason for the differences in the outcome variables are caused by the different conditions. Therefore, researchers should choose the experimental design over other design types whenever possible. However, the nature of the independent variable does not always allow for manipulation. In those cases, researchers must be aware of not certifying about causal attribution when their design doesn't allow for it. For example, in observational designs, participants are not assigned randomly to conditions, and so if there are differences found in outcome variables between conditions, it is likely that there is something other than the differences between the conditions that causes the differences in outcomes, that is – a third variable. The same goes for studies with correlational design. (Adér & Mellenbergh, 2008).
Statistical control [edit]
It is best that a process be in reasonable statistical control prior to conducting designed experiments. When this is not possible, proper blocking, replication, and randomization allow for the careful conduct of designed experiments.[28] To control for nuisance variables, researchers institute control checks as additional measures. Investigators should ensure that uncontrolled influences (e.g., source credibility perception) do not skew the findings of the study. A manipulation check is one example of a control check. Manipulation checks allow investigators to isolate the chief variables to strengthen support that these variables are operating as planned.
One of the most important requirements of experimental research designs is the necessity of eliminating the effects of spurious, intervening, and antecedent variables. In the most basic model, cause (X) leads to effect (Y). But there could be a third variable (Z) that influences (Y), and X might not be the true cause at all. Z is said to be a spurious variable and must be controlled for. The same is true for intervening variables (a variable in between the supposed cause (X) and the effect (Y)), and anteceding variables (a variable prior to the supposed cause (X) that is the true cause). When a third variable is involved and has not been controlled for, the relation is said to be a zero order relationship. In most practical applications of experimental research designs there are several causes (X1, X2, X3). In most designs, only one of these causes is manipulated at a time.
Experimental designs after Fisher [edit]
Some efficient designs for estimating several main effects were found independently and in near succession by Raj Chandra Bose and K. Kishen in 1940 at the Indian Statistical Institute, but remained little known until the Plackett–Burman designs were published in Biometrika in 1946. About the same time, C. R. Rao introduced the concepts of orthogonal arrays as experimental designs. This concept played a central role in the development of Taguchi methods by Genichi Taguchi, which took place during his visit to Indian Statistical Institute in early 1950s. His methods were successfully applied and adopted by Japanese and Indian industries and subsequently were also embraced by US industry albeit with some reservations.
In 1950, Gertrude Mary Cox and William Gemmell Cochran published the book Experimental Designs, which became the major reference work on the design of experiments for statisticians for years afterwards.
Developments of the theory of linear models have encompassed and surpassed the cases that concerned early writers. Today, the theory rests on advanced topics in linear algebra, algebra and combinatorics.
As with other branches of statistics, experimental design is pursued using both frequentist and Bayesian approaches: In evaluating statistical procedures like experimental designs, frequentist statistics studies the sampling distribution while Bayesian statistics updates a probability distribution on the parameter space.
Some important contributors to the field of experimental designs are C. S. Peirce, R. A. Fisher, F. Yates, R. C. Bose, A. C. Atkinson, R. A. Bailey, D. R. Cox, G. E. P. Box, W. G. Cochran, W. T. Federer, V. V. Fedorov, A. S. Hedayat, J. Kiefer, O. Kempthorne, J. A. Nelder, Andrej Pázman, Friedrich Pukelsheim, D. Raghavarao, C. R. Rao, Shrikhande S. S., J. N. Srivastava, William J. Studden, G. Taguchi and H. P. Wynn.[29]
The textbooks of D. Montgomery, R. Myers, and G. Box/W. Hunter/J.S. Hunter have reached generations of students and practitioners. [30] [31] [32] [33] [34]
Some discussion of experimental design in the context of system identification (model building for static or dynamic models) is given in[35] and [36]
Human participant constraints [edit]
Laws and ethical considerations preclude some carefully designed experiments with human subjects. Legal constraints are dependent on jurisdiction. Constraints may involve institutional review boards, informed consent and confidentiality affecting both clinical (medical) trials and behavioral and social science experiments.[37] In the field of toxicology, for example, experimentation is performed on laboratory animals with the goal of defining safe exposure limits for humans.[38] Balancing the constraints are views from the medical field.[39] Regarding the randomization of patients, "... if no one knows which therapy is better, there is no ethical imperative to use one therapy or another." (p 380) Regarding experimental design, "...it is clearly not ethical to place subjects at risk to collect data in a poorly designed study when this situation can be easily avoided...". (p 393)
See also [edit]
- Adversarial collaboration
- Bayesian experimental design
- Block design
- Box–Behnken design
- Central composite design
- Clinical trial
- Clinical study design
- Computer experiment
- Control variable
- Controlling for a variable
- Experimetrics (econometrics-related experiments)
- Factor analysis
- Fractional factorial design
- Glossary of experimental design
- Grey box model
- Industrial engineering
- Instrument effect
- Law of large numbers
- Manipulation checks
- Multifactor design of experiments software
- One-factor-at-a-time method
- Optimal design
- Plackett–Burman design
- Probabilistic design
- Protocol (natural sciences)
- Quasi-experimental design
- Randomized block design
- Randomized controlled trial
- Research design
- Robust parameter design
- Sample size determination
- Supersaturated design
- Royal Commission on Animal Magnetism
- Survey sampling
- System identification
- Taguchi methods
References [edit]
- ^ Peirce, Charles Sanders (1887). "Illustrations of the Logic of Science". Open Court (10 June 2014). ISBN 0812698495.
- ^ Peirce, Charles Sanders (1883). "A Theory of Probable Inference". In C. S. Peirce (Ed.), Studies in logic by members of the Johns Hopkins University (p. 126–181). Little, Brown and Co (1883)
- ^ Stigler, Stephen M. (1978). "Mathematical statistics in the early States". Annals of Statistics. 6 (2): 239–65 [248]. doi:10.1214/aos/1176344123. JSTOR 2958876. MR 0483118.
Indeed, Pierce's work contains one of the earliest explicit endorsements of mathematical randomization as a basis for inference of which I am aware (Peirce, 1957, pages 216–219
- ^ a b Peirce, Charles Sanders; Jastrow, Joseph (1885). "On Small Differences in Sensation". Memoirs of the National Academy of Sciences. 3: 73–83.
- ^ a b of Hacking, Ian (September 1988). "Telepathy: Origins of Randomization in Experimental Design". Isis. 79 (3): 427–451. doi:10.1086/354775. JSTOR 234674. MR 1013489. S2CID 52201011.
- ^ a b Stephen M. Stigler (November 1992). "A Historical View of Statistical Concepts in Psychology and Educational Research". American Journal of Education. 101 (1): 60–70. doi:10.1086/444032. JSTOR 1085417. S2CID 143685203.
- ^ a b Trudy Dehue (December 1997). "Deception, Efficiency, and Random Groups: Psychology and the Gradual Origination of the Random Group Design". Isis. 88 (4): 653–673. doi:10.1086/383850. PMID 9519574. S2CID 23526321.
- ^ Peirce, C. S. (1876). "Note on the Theory of the Economy of Research". Coast Survey Report: 197–201. , actually published 1879, NOAA PDF Eprint.
Reprinted in Collected Papers 7, paragraphs 139–157, also in Writings 4, pp. 72–78, and in Peirce, C. S. (July–August 1967). "Note on the Theory of the Economy of Research". Operations Research. 15 (4): 643–648. doi:10.1287/opre.15.4.643. JSTOR 168276. - ^ Guttorp, P.; Lindgren, G. (2009). "Karl Pearson and the Scandinavian school of statistics". International Statistical Review. 77: 64. CiteSeerX10.1.1.368.8328. doi:10.1111/j.1751-5823.2009.00069.x.
- ^ Smith, Kirstine (1918). "On the standard deviations of adjusted and interpolated values of an observed polynomial function and its constants and the guidance they give towards a proper choice of the distribution of observations". Biometrika. 12 (1–2): 1–85. doi:10.1093/biomet/12.1-2.1.
- ^ Johnson, N.L. (1961). "Sequential analysis: a survey." Journal of the Royal Statistical Society, Series A. Vol. 124 (3), 372–411. (pages 375–376)
- ^ Wald, A. (1945) "Sequential Tests of Statistical Hypotheses", Annals of Mathematical Statistics, 16 (2), 117–186.
- ^ a b Herman Chernoff, Sequential Analysis and Optimal Design, SIAM Monograph, 1972.
- ^ Zacks, S. (1996) "Adaptive Designs for Parametric Models". In: Ghosh, S. and Rao, C. R., (Eds) (1996). "Design and Analysis of Experiments," Handbook of Statistics, Volume 13. North-Holland. ISBN 0-444-82061-2. (pages 151–180)
- ^ Robbins, H. (1952). "Some Aspects of the Sequential Design of Experiments". Bulletin of the American Mathematical Society. 58 (5): 527–535. doi:10.1090/S0002-9904-1952-09620-8.
- ^ Miller, Geoffrey (2000). The Mating Mind: how sexual choice shaped the evolution of human nature, London: Heineman, ISBN 0-434-00741-2 (also Doubleday, ISBN 0-385-49516-1) "To biologists, he was an architect of the 'modern synthesis' that used mathematical models to integrate Mendelian genetics with Darwin's selection theories. To psychologists, Fisher was the inventor of various statistical tests that are still supposed to be used whenever possible in psychology journals. To farmers, Fisher was the founder of experimental agricultural research, saving millions from starvation through rational crop breeding programs." p.54.
- ^ Creswell, J.W. (2008), Educational research: Planning, conducting, and evaluating quantitative and qualitative research (3rd edition), Upper Saddle River, NJ: Prentice Hall. 2008, p. 300. ISBN 0-13-613550-1
- ^ Dr. Hani (2009). "Replication study". Archived from the original on 2 June 2012. Retrieved 27 October 2011.
- ^ Burman, Leonard E.; Robert W. Reed; James Alm (2010), "A call for replication studies", Public Finance Review, 38 (6): 787–793, doi:10.1177/1091142110385210, S2CID 27838472, retrieved 27 October 2011
- ^ Hotelling, Harold (1944). "Some Improvements in Weighing and Other Experimental Techniques". Annals of Mathematical Statistics. 15 (3): 297–306. doi:10.1214/aoms/1177731236.
- ^ Giri, Narayan C.; Das, M. N. (1979). Design and Analysis of Experiments. New York, N.Y: Wiley. pp. 350–359. ISBN9780852269145.
- ^ a b Jack Sifri (8 December 2014). "How to Use Design of Experiments to Create Robust Designs With High Yield". youtube.com . Retrieved 11 February 2015.
- ^ Simmons, Joseph; Leif Nelson; Uri Simonsohn (November 2011). "False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant". Psychological Science. 22 (11): 1359–1366. doi:10.1177/0956797611417632. ISSN 0956-7976. PMID 22006061.
- ^ "Science, Trust And Psychology in Crisis". KPLU. 2 June 2014. Archived from the original on 14 July 2014. Retrieved 12 June 2014.
- ^ "Why Statistically Significant Studies Can Be Insignificant". Pacific Standard. 4 June 2014. Retrieved 12 June 2014.
- ^ Chris Chambers (10 June 2014). "Physics envy: Do 'hard' sciences hold the solution to the replication crisis in psychology?". theguardian.com . Retrieved 12 June 2014.
- ^ Ader, Mellenberg & Hand (2008) "Advising on Research Methods: A consultant's companion"
- ^ Bisgaard, S (2008) "Must a Process be in Statistical Control before Conducting Designed Experiments?", Quality Engineering, ASQ, 20 (2), pp 143–176
- ^ Giri, Narayan C.; Das, M. N. (1979). Design and Analysis of Experiments. New York, N.Y: Wiley. pp. 53, 159, 264. ISBN9780852269145.
- ^ Montgomery, Douglas (2013). Design and analysis of experiments (8th ed.). Hoboken, NJ: John Wiley & Sons, Inc. ISBN9781118146927.
- ^ Walpole, Ronald E.; Myers, Raymond H.; Myers, Sharon L.; Ye, Keying (2007). Probability & statistics for engineers & scientists (8 ed.). Upper Saddle River, NJ: Pearson Prentice Hall. ISBN978-0131877115.
- ^ Myers, Raymond H.; Montgomery, Douglas C.; Vining, G. Geoffrey; Robinson, Timothy J. (2010). Generalized linear models : with applications in engineering and the sciences (2 ed.). Hoboken, N.J.: Wiley. ISBN978-0470454633.
- ^ Box, George E.P.; Hunter, William G.; Hunter, J. Stuart (1978). Statistics for Experimenters : An Introduction to Design, Data Analysis, and Model Building. New York: Wiley. ISBN978-0-471-09315-2.
- ^ Box, George E.P.; Hunter, William G.; Hunter, J. Stuart (2005). Statistics for Experimenters : Design, Innovation, and Discovery (2 ed.). Hoboken, N.J.: Wiley. ISBN978-0471718130.
- ^ Spall, J. C. (2010). "Factorial Design for Efficient Experimentation: Generating Informative Data for System Identification". IEEE Control Systems Magazine. 30 (5): 38–53. doi:10.1109/MCS.2010.937677. S2CID 45813198.
- ^ Pronzato, L (2008). "Optimal experimental design and some related control problems". Automatica. 44 (2): 303–325. arXiv:0802.4381. doi:10.1016/j.automatica.2007.05.016. S2CID 1268930.
- ^ Moore, David S.; Notz, William I. (2006). Statistics : concepts and controversies (6th ed.). New York: W.H. Freeman. pp. Chapter 7: Data ethics. ISBN9780716786368.
- ^ Ottoboni, M. Alice (1991). The dose makes the poison : a plain-language guide to toxicology (2nd ed.). New York, N.Y: Van Nostrand Reinhold. ISBN978-0442006600.
- ^ Glantz, Stanton A. (1992). Primer of biostatistics (3rd ed.). ISBN978-0-07-023511-3.
Sources [edit]
- Peirce, C. S. (1877–1878), "Illustrations of the Logic of Science" (series), Popular Science Monthly, vols. 12–13. Relevant individual papers:
- (1878 March), "The Doctrine of Chances", Popular Science Monthly, v. 12, March issue, pp. 604–615. Internet Archive Eprint.
- (1878 April), "The Probability of Induction", Popular Science Monthly, v. 12, pp. 705–718. Internet Archive Eprint.
- (1878 June), "The Order of Nature", Popular Science Monthly, v. 13, pp. 203–217.Internet Archive Eprint.
- (1878 August), "Deduction, Induction, and Hypothesis", Popular Science Monthly, v. 13, pp. 470–482. Internet Archive Eprint.
- (1883), "A Theory of Probable Inference", Studies in Logic, pp. 126–181, Little, Brown, and Company. (Reprinted 1983, John Benjamins Publishing Company, ISBN 90-272-3271-7)
External links [edit]
- A chapter from a "NIST/SEMATECH Handbook on Engineering Statistics" at NIST
- Box–Behnken designs from a "NIST/SEMATECH Handbook on Engineering Statistics" at NIST
- Detailed mathematical developments of most common DoE in the Opera Magistris v3.6 online reference Chapter 15, section 7.4, ISBN 978-2-8399-0932-7.
Fundamental Concepts in the Design of Experiments 5th Edition
Source: https://en.wikipedia.org/wiki/Design_of_experiments